ChatGPT can now produce images! 🤯 And they are shockingly accurate. Today I’m trying out the new image generation feature (DALL-E 3!), and I’m definitely thrilled by the possibilities. This is way more exciting than Midjourney or standalone Stable Diffusion. And yet again I feel distracted from my recent project (on which I will update you in time). Yay!
Ok, so this development is already a month (or so) old, so I’m a bit late to the party. But hey, better late than never.
In this article I’m including some memes and illustrations (particularly interesting for POD designers, and, well, illustrators).
How To Use DALL-E 3
First things first — here is how you can access DALL-E 3. It’s fairly simple.
- Go on ChatGPT. You need to have the subscription in order to use DALL-E 3, at least at the time of writing this.
- Make sure to select ChatGPT 4 as a model in the upper left corner.
- Write a prompt! It’s perfectly fine to keep it simple, you will achieve interesting results anyway, as ChatGPT will do the thinking for you
Example Prompts for DALL-E 3
A simple short prompt will go a long way. Try things like:
- Create an image of a hedgehog in the rain
- Make a meme about a messy kitchen
- Create a logo for my bakery
- Create a meme about my friend Janet who is always late
Especially the latter point is proving to be very interesting for me, as I love surprising my friends with some crazy imagery. Best thing you can do is experiment a bit, and see what comes out. Oftentimes the results are entertaining.
Memes
So the first thing I’ve tried was to generate memes, as I keep seeing AI-generated memes all over my social media.

And the beautiful thing here is that ChatGPT comes up with its own prompt, adding new thoughts to your idea. At this point, it basically does all the (conceptual) thinking.

You might be wondering: how is DALL-E handling text / alphabet characters displayed in images? Well, it got waay better, although of course there are occasional glitches. Compared to earlier versions of DALL-E though this is a significant improvement. I also like the font used here.
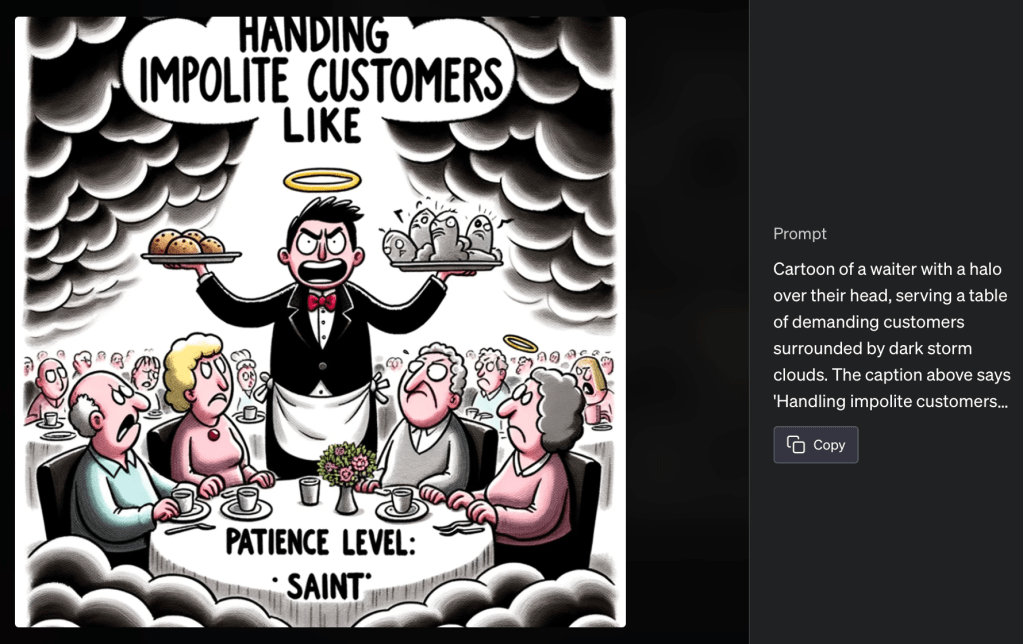
As you can probably guess, the sky is the limit here. Generating this type of content like this could be a game-changer for anyone who wants to run, say, a meme Instagram account.
Illustrations and Shirt Designs
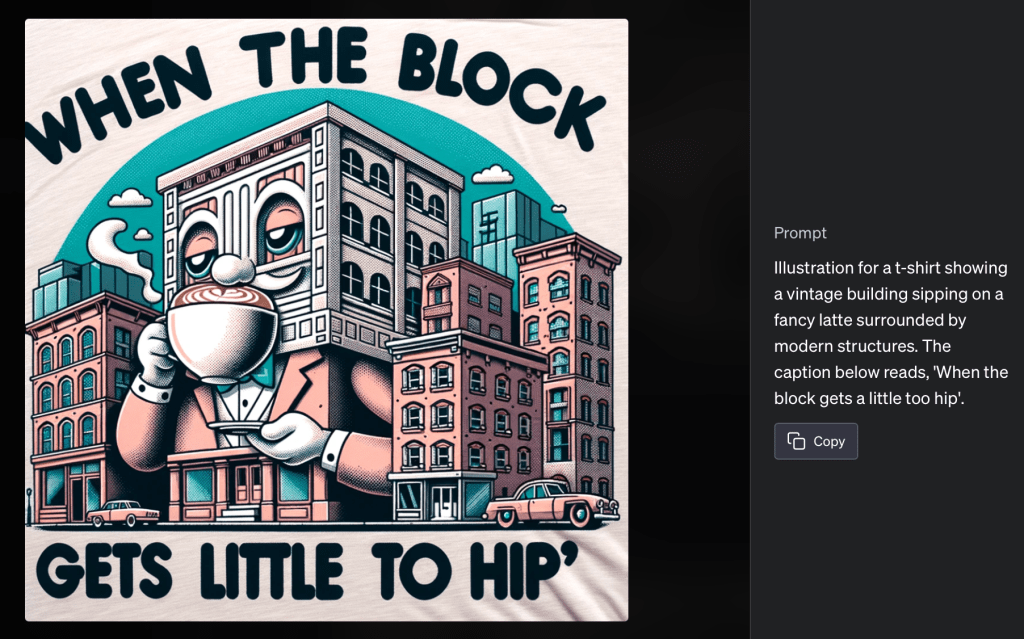
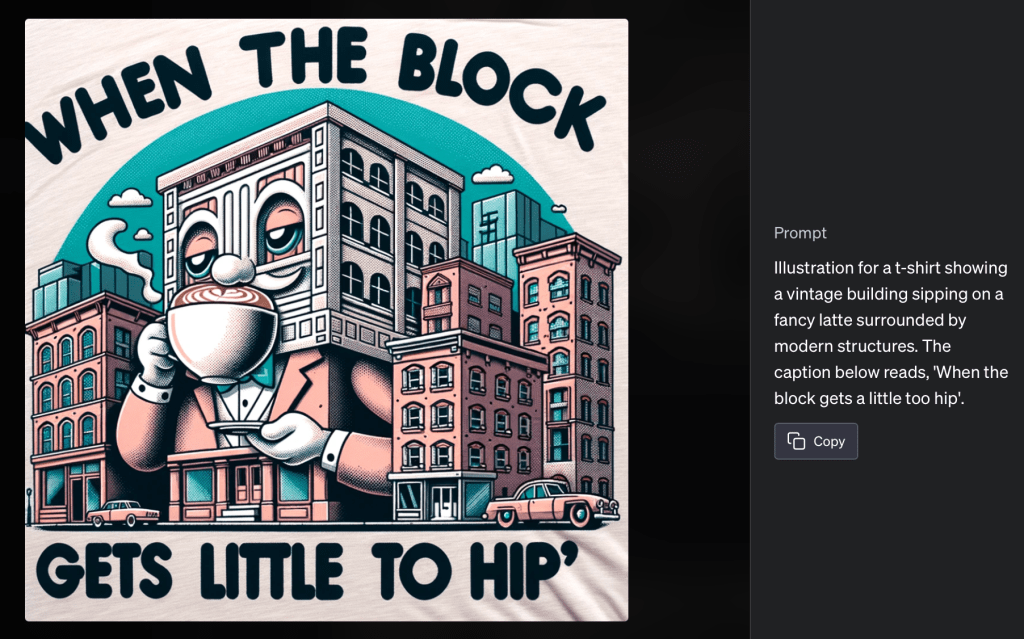
But wait, there’s more. Memes obviously weren’t enough, so I went straight ahead to shirt design illustrations. And as a “seasoned artist”, I have to say I’m impressed. To check for possible copyright breaches, I performed a Google image search for several of these designs, and found nothing similar enough.
For this one, I told ChatGPT to create a meme about gentrification:
And here is an illustration about marketing, or made FOR the marketer. This one is a bit more glitchy, maybe because of the amount of words involved:

And while it has errors and glitches, it’s conceptually still a great idea that could work well on a shirt. Personally for me I have decided that I definitely will use this as an inspiration for my actual designs.
Of course I made more than these images, so if you’re curious, you might as well ask me. You can get in contact via my contact form
or Instagram, for example: https://www.instagram.com/swetlana_ai/
Here’s one more about boomers and millennials:

ChatGPT and DALL-E 3
Here’s what all the fuzz is about: ChatGPT now offers a unique image creation feature for Plus and Enterprise users. Simply describe your vision, and ChatGPT will provide visuals for you to refine and request revisions in the chat.
DALL·E 3 is a highly advanced image model resulting from extensive research, offering visually stunning and detailed images. It excels in handling detailed prompts, supports various aspect ratios, and focuses more on user-supplied captions.
With DALL·E 3, you can unleash your creativity like never before. The only BUT: it doesn’t replicate the style of living artists. Additionally, you have the option to exclude your images from future model training. Learn more in their research paper here.
Here’s the summary of the research paper:
Recent advancements in generative modeling have significantly improved text-to-image generative models. These improvements stem from two main approaches: using sampling-based methods like autoregressive generative modeling or diffusion processes, which break down image generation into manageable steps for neural networks. Additionally, researchers have developed image generators based on self-attention layers, separating image generation from convolutional spatial biases and leveraging transformer scaling properties.
When coupled with large datasets, these approaches enable the training of text-to-image models that can produce imagery approaching human-quality photos and artwork. However, a key challenge in this field is “prompt following,” where models often struggle to capture word meanings, order, or context in given captions.
Several works have highlighted this challenge, proposing various solutions. This paper introduces a novel approach to address prompt following: caption improvement. The authors believe that the poor quality of text-image pairings in training datasets is a fundamental issue. To tackle this, they develop a robust image captioning system to generate detailed, accurate descriptions for images, enhancing the dataset’s captions. Subsequently, they train text-to-image models on this improved dataset.
While training on synthetic data is not new, this work focuses on the development of a descriptive image captioning system and assesses the impact of using synthetic captions in training generative models. The paper primarily evaluates the enhanced prompt following capabilities of DALL-E 3, achieved through training on highly descriptive generated captions. It does not delve into the technical details of the DALL-E 3 model but provides an overview of the training strategy, evaluations, and discussions of limitations and risks.

Leave a comment